Search in records: Filter, Offset, Limit and Order
When working with a large number of recordsIn Boost.space, a record is a single data entry within a module, like a row in a database. For example, a contact in the Contacts module or a task in the Tasks module., you often don’t need all the data at once — and in many cases, loading everything could even stop the scenarioA specific connection between applications in which data can be transferred. Two types of scenarios: active/inactive. from running.
That’s why Boost.spaceA platform that centralizes and synchronizes company data from internal and external sources, offering a suite of modules and addons for project management, CRM, data visualization, and more. Has many features to optimize your workflow! allows you to define how data should be searched, limited, ordered, and retrieved from a modulea module is an application or tool designed to handle specific business functions, such as CRM, project management, or inventory. The system's modular architecture allows you to activate only the modules you need, enabling customization and scalability as your business requirements evolve..
Using Filter, Offset, Limit, and Order, you can specify which records to work with, where to start, how many to retrieve at a time, and how they should be sorted. This approach allows you to handle large datasets in manageable steps.
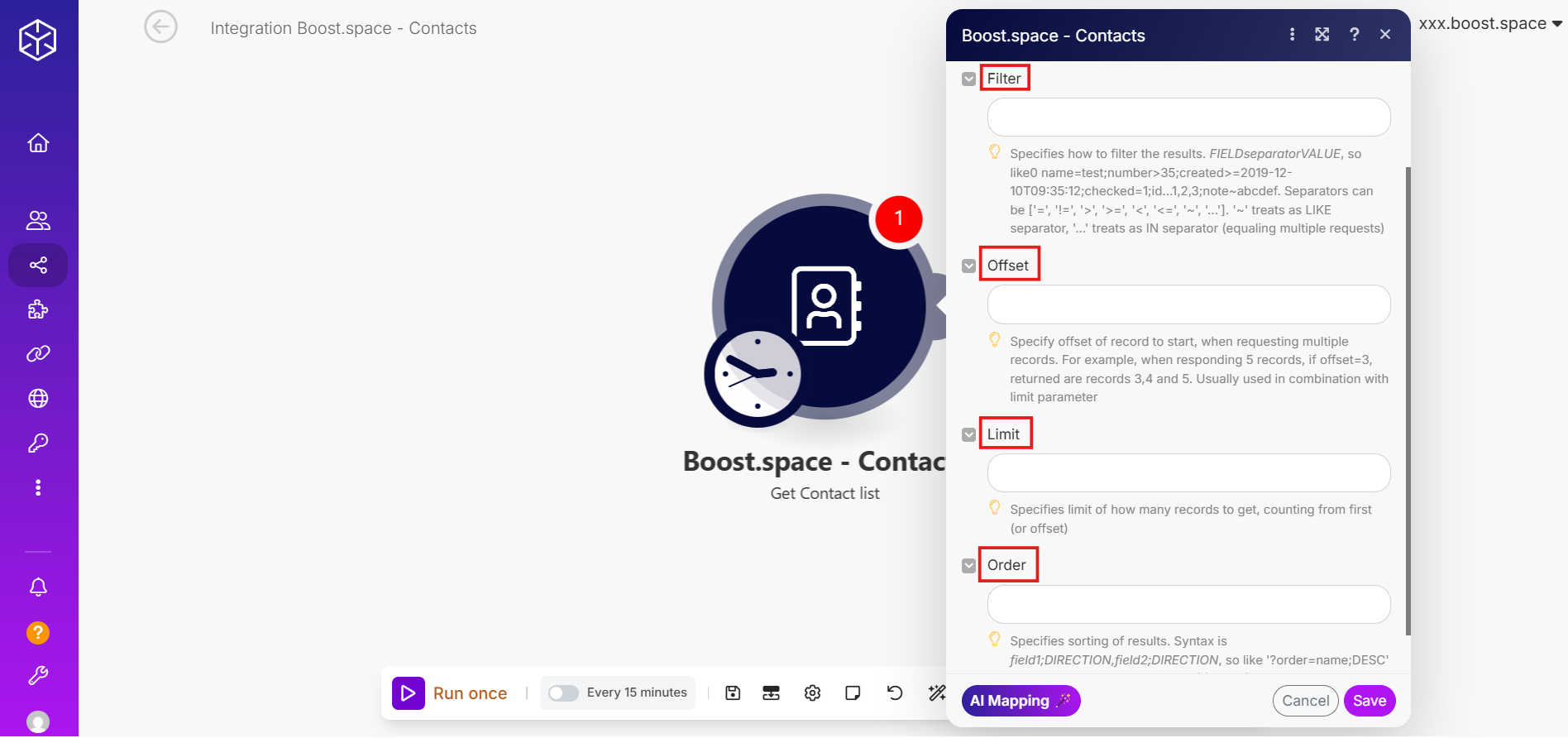
Filter
Filtering makes it possible to search only for records that meet specific conditions. Instead of scanning through all existing data, you can use filters to find exactly what you need. The filtering runs through a GET request that retrieves only those itemsItems are rows in records (order/request/invoice/purchase...) matching your filter parameters.
You can filter by both basic fields and custom fieldsA feature in Boost.space that allows administrators to define and manage additional data fields within each module, tailoring the system to specific organizational needs., as well as by SpaceIn Boost.space, a space is a subunit within a module that helps organize and categorize data, ensuring clarity even with large volumes. For example, within the Contacts module, you might have spaces like "Client Database" or "Supplier Database." Access to each space is restricted to users who have created it or have been granted access. ID. Just keep in mind that field names are case-sensitive, so for example, spaceId will work, but spaceid will not.
Filters can include standard comparison operators such as =, !=, >, <, and logical operators like & (AND) or | (OR) for combining multiple conditions.
Filtering by Custom Fields
Boost.space IntegratorPart of the Boost.space system, where you can create your connections and automate your processes. supports filtering by custom fields, allowing you to include your own data fields in queries.
Examples:
customField.test-xytest-xy
Both forms are valid.
Special Characters:
Filters cannot contain two special characters in a row. For example: customField.xyz-_CustomField will not work. A valid example would be customField.xyz-CustomField, which avoids consecutive special characters.
To see the full list of supported operators, examples, and detailed instructions, see the article Filtering in Boost.space Integrator.
Offset
The Offset parameter tells the system where to start reading data from.
It defines the recordIn Boost.space, a record is a single data entry within a module, like a row in a database. For example, a contact in the Contacts module or a task in the Tasks module. position from which the scenario begins. For instance, if you set an offset of 100, the scenario will skip the first 100 records and start processing from the 101st one.
This is especially useful when you’re working with large datasets that cannot be processed in one run. Offset lets you continue processing data in smaller parts without repeating already processed records.
Limit
Limit defines how many records should be retrieved or processed in one scenario run.
If you set limit=100, only 100 records will be returned — even if there are thousands available.
The Limit parameter defines how many records should be retrieved or processed in a single scenario run. If you set limit=100, only 100 records will be returned, even if there are more available.
This helps prevent timeouts or slowdowns when a scenario handles a large number of records. It’s best to set the limit low enough so that each run finishes reliably, but high enough to process a reasonable number of records at a time.
Limit is often used together with Offset to create a sequence of smaller batches — for example, fetching 100 records at a time until all data has been processed.
Order
Note: The Order functionality is currently under development.
The Order parameter determines how records are sorted before they are returned. You can choose a field to sort by and the direction: ascending (ASC) or descending (DESC). Sorting ensures that records appear in the order you need, which can be important when processing data step by step.
It is also possible to sort by multiple fields. In this case, the system sorts records first by the first field, and if two or more records have the same value in that field, it then sorts by the next field in the list.
Suppose you want to sort a list of people first by last name and then by first name. This ensures that if two people have the same last name, they will be ordered alphabetically by their first names:
Name;ASC,firstname;ASC
Here, ASC means ascending order. The system first sorts all records by last name, and when there are duplicates, it applies the second part of the order to sort by first name.
Example
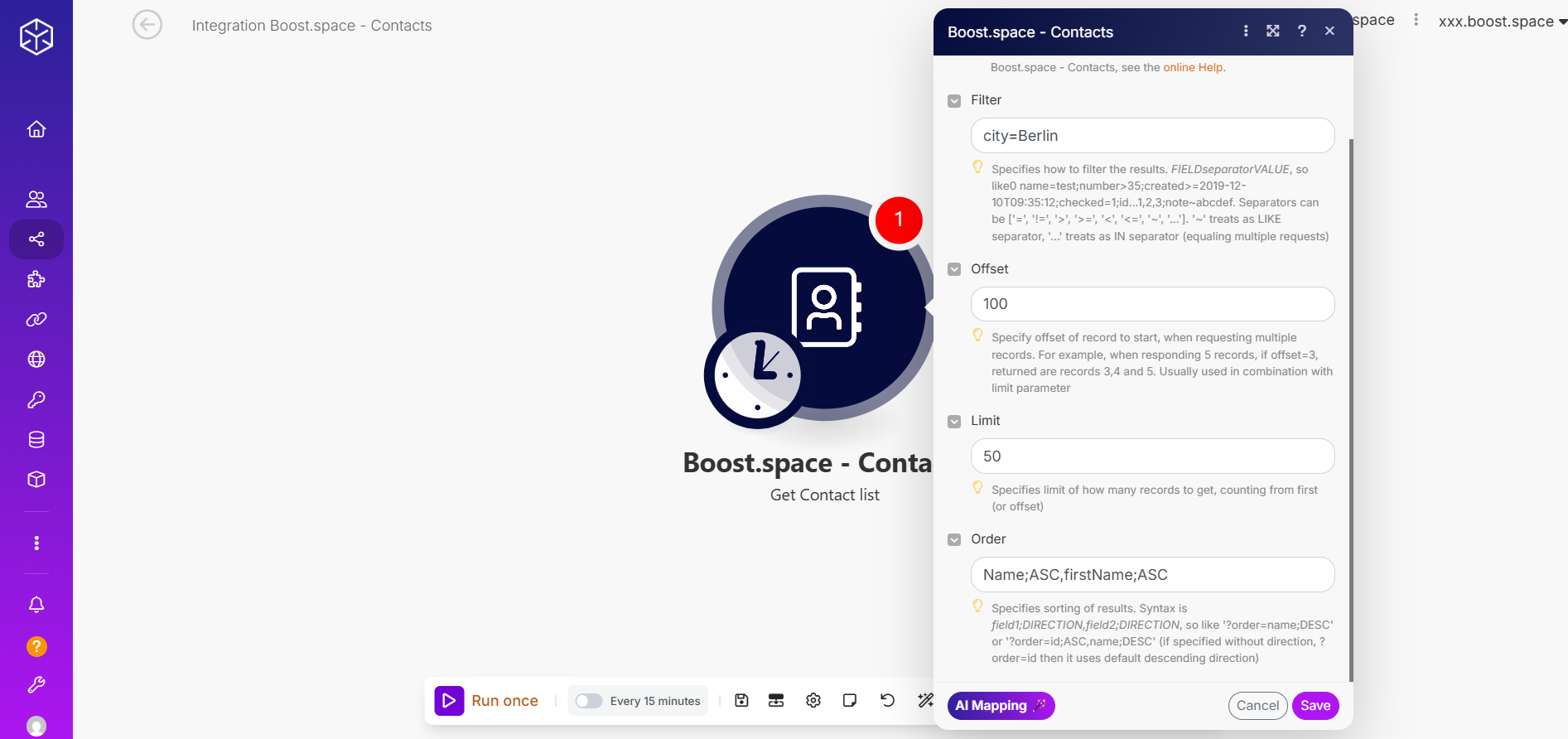
Suppose you want to retrieve a subset of contacts from your dataset with the following requirements:
- Only include people who live in Berlin.
- Start retrieving records from the 101st record.
- Retrieve 50 records in this run.
- Sort the results first by last name, then by first name, both in ascending order.
Here’s how the request would look:
Explanation:
city=Berlin→ Filter applied to select only records for people who live in Berlin.offset=100→ Skips the first 100 records and starts at record 101.limit=50→ Only 50 records will be returned in this run.order=Name;ASC,firstName;ASC→ Sorts results by last name first, and for records with the same last name, sorts by first name.
Using Filter, Offset, Limit, and Order provides control over which records are retrieved and how they are returned. Filters select records that meet specific conditions. Offset sets the starting point, Limit defines the number of records to retrieve, and Order determines the sorting sequence.
Each parameter can be used independently, depending on the needs of your scenario. Combining them is optional and allows you to handle larger datasets in parts, while keeping results organized.