A Guide to Data ConsolidationA Boost.space feature that merges data from multiple sources, allowing integration of diverse datasets into a unified view. Using API token prioritization, it determines which data sources overwrite others, ensuring accuracy and consistency across your system.: Prioritizing Tokens for Accurate and Efficient Updates
Data consolidation is a crucial aspect of managing and organizing data within a system. It involves the merging and prioritization of data from multiple sources or fields to create a unified and up-to-date dataset. In this article, we will explore the process of data flow and how to prioritize tokens to ensure accurate and efficient data updates.
If you don’t know how our interface that is showing your integrations works, then we recommend you first take a look at our article on Data Flow view.
Video
TokenA secure code used to authenticate and authorize access to API endpoints, enabling users to connect with third-party applications. Prioritization:
Before diving into the data consolidation process, it is essential to have an API tokenA secure code used to authenticate and authorize access to API endpoints, enabling users to connect with third-party applications. created. If you are unsure about how to create your own token, please refer to the documentation on token creation.
It is important to note that token prioritization only affects the overwriting of data and has no impact on data creation. Therefore, it specifically applies to “update” scenariosA specific connection between applications in which data can be transferred. Two types of scenarios: active/inactive.. Tokens do not affect the manual overwriting of data in the system, and data can always be overwritten manually regardless of token prioritization.
Data Consolidation Process:
To consolidate your data, follow the steps outlined below:
- Open the modulea module is an application or tool designed to handle specific business functions, such as CRM, project management, or inventory. The system's modular architecture allows you to activate only the modules you need, enabling customization and scalability as your business requirements evolve. or addonTools in the Boost.space system that extend primary modules with additional functionality, allowing customization of workflows to fit your company's needs. They offer features such as creating forms, managing projects, and facilitating communication. Each addon integrates with others, enhancing the overall functionality of your workspace. where you want to consolidate your data.
- Locate the “Flow” option in the top bar and click on it.
- In the first column, you can select the priority of the token.
Token Prioritization Interface:
Upon clicking the “Flow” option, a table will appear in the middle of the interface. Click on the button to open the functionFunctions you can use in Boost.space Integrator - create, update, delete, get, search. of Data consolidation. This table allows you to select the data you wish to consolidate by field name and provides options for further customization.
- Select the desired data to consolidate by a field name in the table.
- Click on the gear wheel icon to access the token prioritization interface.
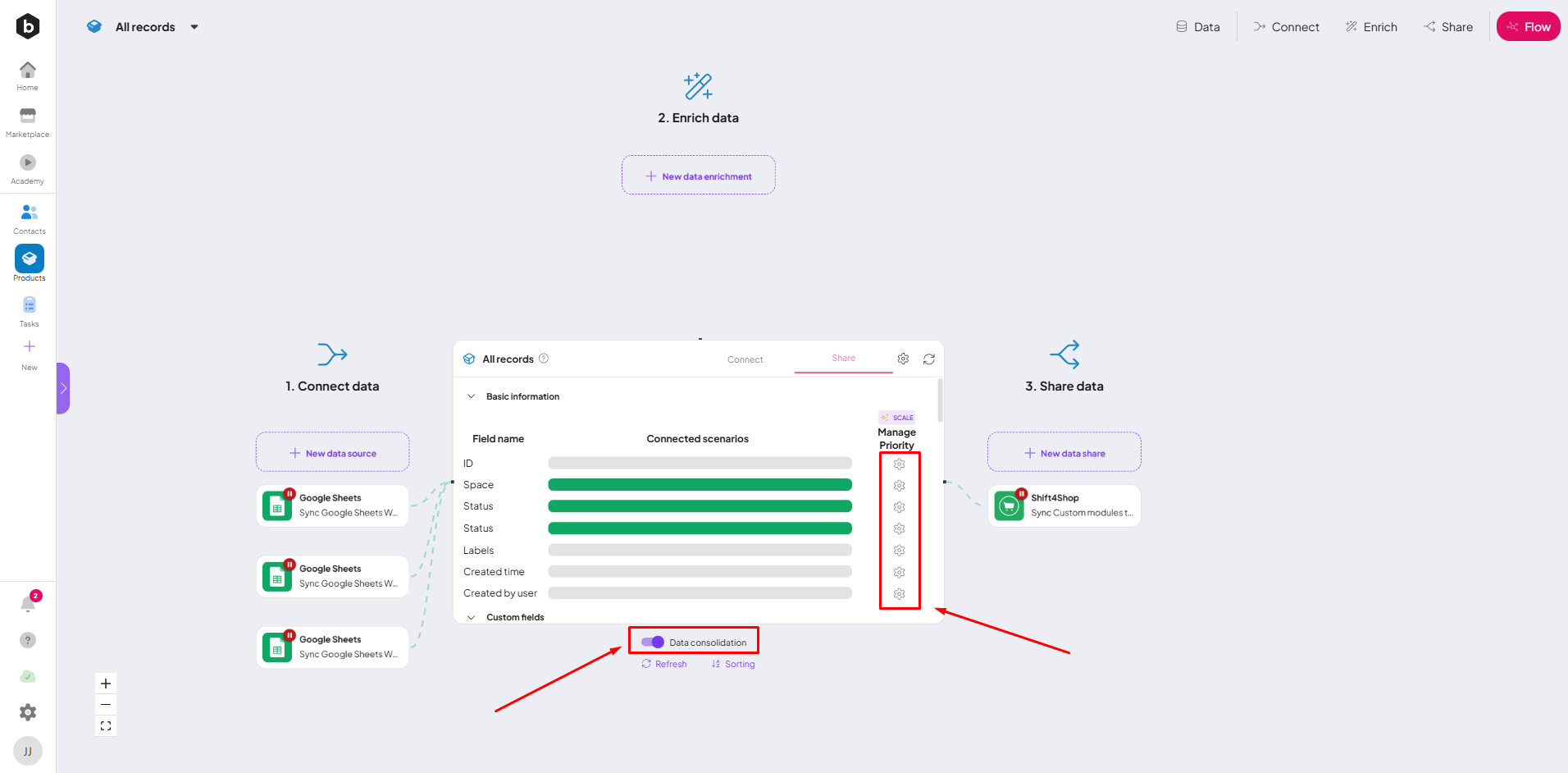
In the token prioritization interface, you will find a table displaying the priorities assigned to each token. The available priorities are: lowest, lower, low, medium, high, higher, and highest. You can edit these priorities as per your requirements.
Other Adjustable Settings:
The token prioritization interface also offers additional adjustable settings to enhance your data consolidation process. These settings include:
- Navigating to specific scenarios: By double-clicking on a scenarioA specific connection between applications in which data can be transferred. Two types of scenarios: active/inactive., you will be directed to that particular scenario in the IntegratorPart of the Boost.space system, where you can create your connections and automate your processes., facilitating a focused review and adjustment process.
- Data import and export toggling: You can switch between data import and export views within the table. However, it’s important to note that token priority is only relevant for data import scenarios.
Conclusion:
Data consolidation is a vital process for maintaining accurate and up-to-date datasets. By following the steps outlined in this article and leveraging token prioritization, you can efficiently consolidate your data and ensure seamless updates. Remember that tokens do not affect manual data overwriting, and data can always be overwritten manually if needed.
For further assistance or detailed guidance on specific scenarios, please refer to the appropriate sections of the Integrator documentation or contact our support team at support@boost.spaceA platform that centralizes and synchronizes company data from internal and external sources, offering a suite of modules and addons for project management, CRM, data visualization, and more. Has many features to optimize your workflow!.